n8n - Website Content Crawler by Apify
Website Content Crawler from Apify lets you extract text content from websites to feed AI models, LLM applications, vector databases, or Retrieval Augmented Generation (RAG) pipelines. It supports rich formatting using Markdown, cleans the HTML of irrelevant elements, downloads linked files, and integrates with AI ecosystems like Langchain, LlamaIndex, and other LLM frameworks.
To use these modules, you need an API token. You can find your token in the Apify Console under Settings > Integrations. After connecting, you can automate content extraction at scale and incorporate the results into your AI workflows.
Prerequisites
Before you begin, make sure you have:
- An Apify account
- An n8n instance (self‑hosted or cloud)
n8n Cloud setup
This section explains how to install and connect the Apify node when using n8n Cloud.
Install
For n8n Cloud users, installation is even simpler and doesn't require manual package entry. Just search and add the node from the canvas.
- Go to the Canvas and open the nodes panel
- Search for Website Content Crawler by Apify in the community node registry
- Click Install node to add the Apify node to your instance
On n8n Cloud, instance owners can toggle visibility of verified community nodes in the Cloud Admin Panel. Ensure this setting is enabled to install the Website Content Crawler by Apify node.
Connect
- In n8n Cloud, select Create Credential.
- Search for Apify OAuth2 API and select Continue.
- Select Connect my account and authorize with your Apify account.
- n8n automatically retrieves and stores the OAuth2 tokens.
On n8n Cloud, you can use the API key method if you prefer to manage your credentials manually. See the Connect section for n8n self-hosted for detailed API configuration instructions.
With authentication set up, you can now create workflows that incorporate the Apify node.
n8n self-hosted setup
This section explains how to install and connect the Apify node when running your own n8n instance.
Install
If you're running a self-hosted n8n instance, you can install the Apify community node directly from the editor. This process adds the node to your available tools, enabling Apify operations in workflows.
- Open your n8n instance.
- Go to Settings > Community Nodes.
- Select Install.
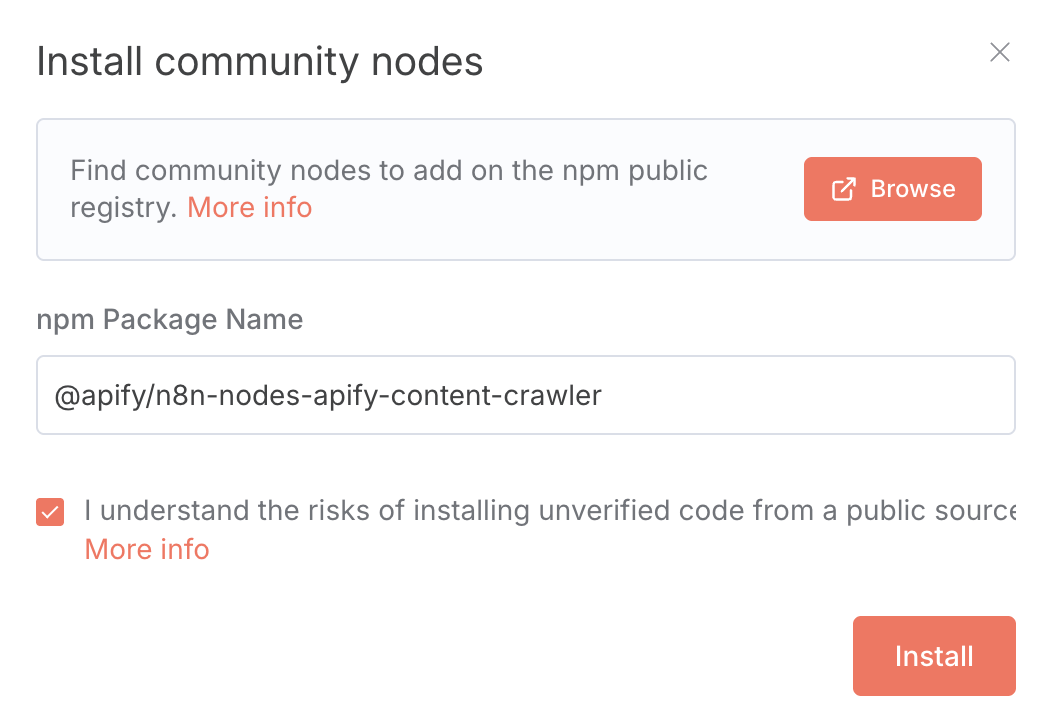
- Enter the npm package name:
@apify/n8n-nodes-apify-content-crawler(for latest version). To install a specific version enter e.g@apify/n8n-nodes-apify-content-crawler@0.0.1. - Agree to the risks of using community nodes and select Install.
- You can now use the node in your workflows.
Connect
-
Create an account at Apify. You can sign up using your email, Gmail, or GitHub account.
-
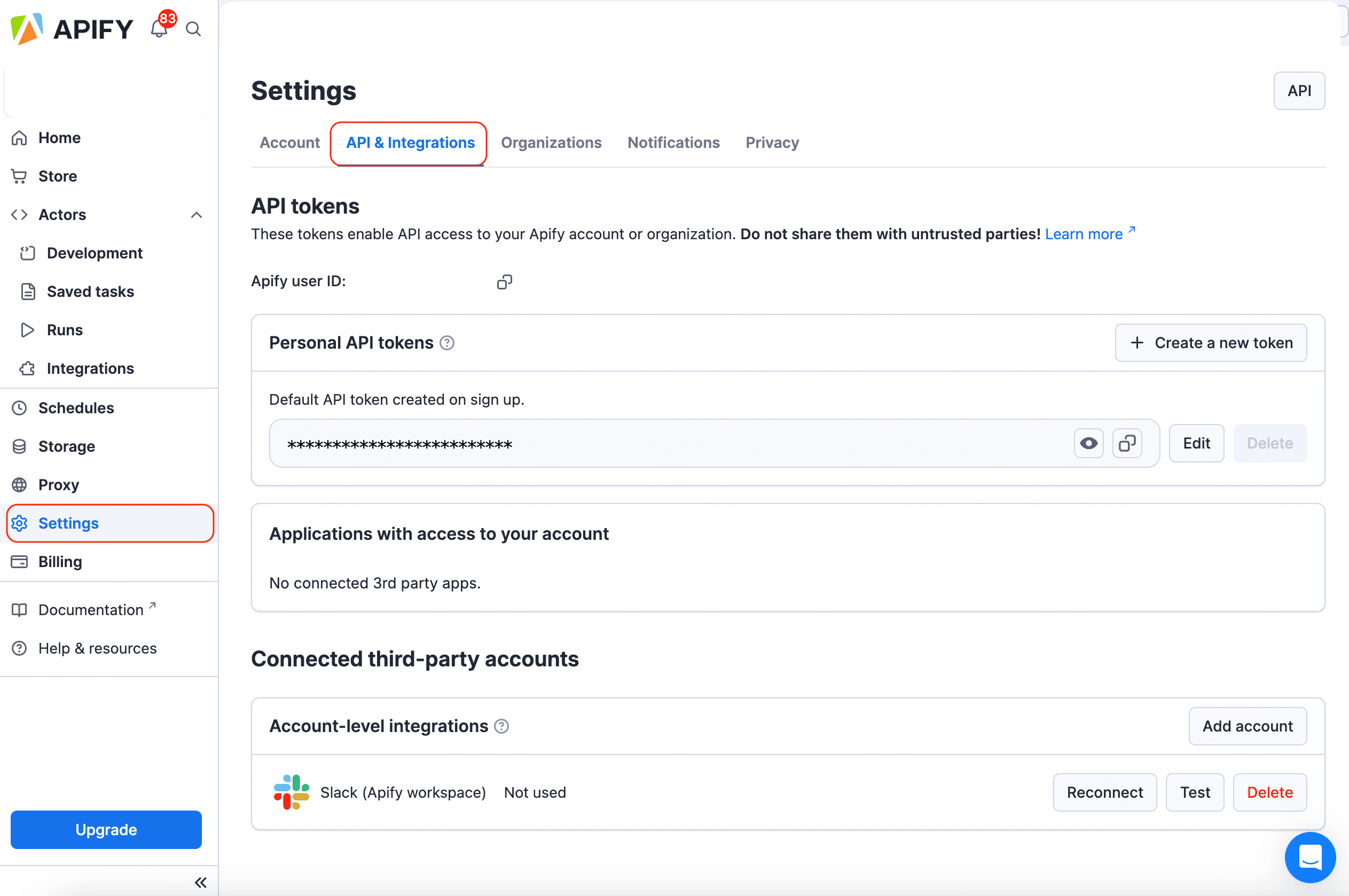
To connect your Apify account to n8n, you can use an OAuth connection (recommended) or an Apify API token. To get the Apify API token, navigate to Settings > API & Integrations in the Apify Console.
-
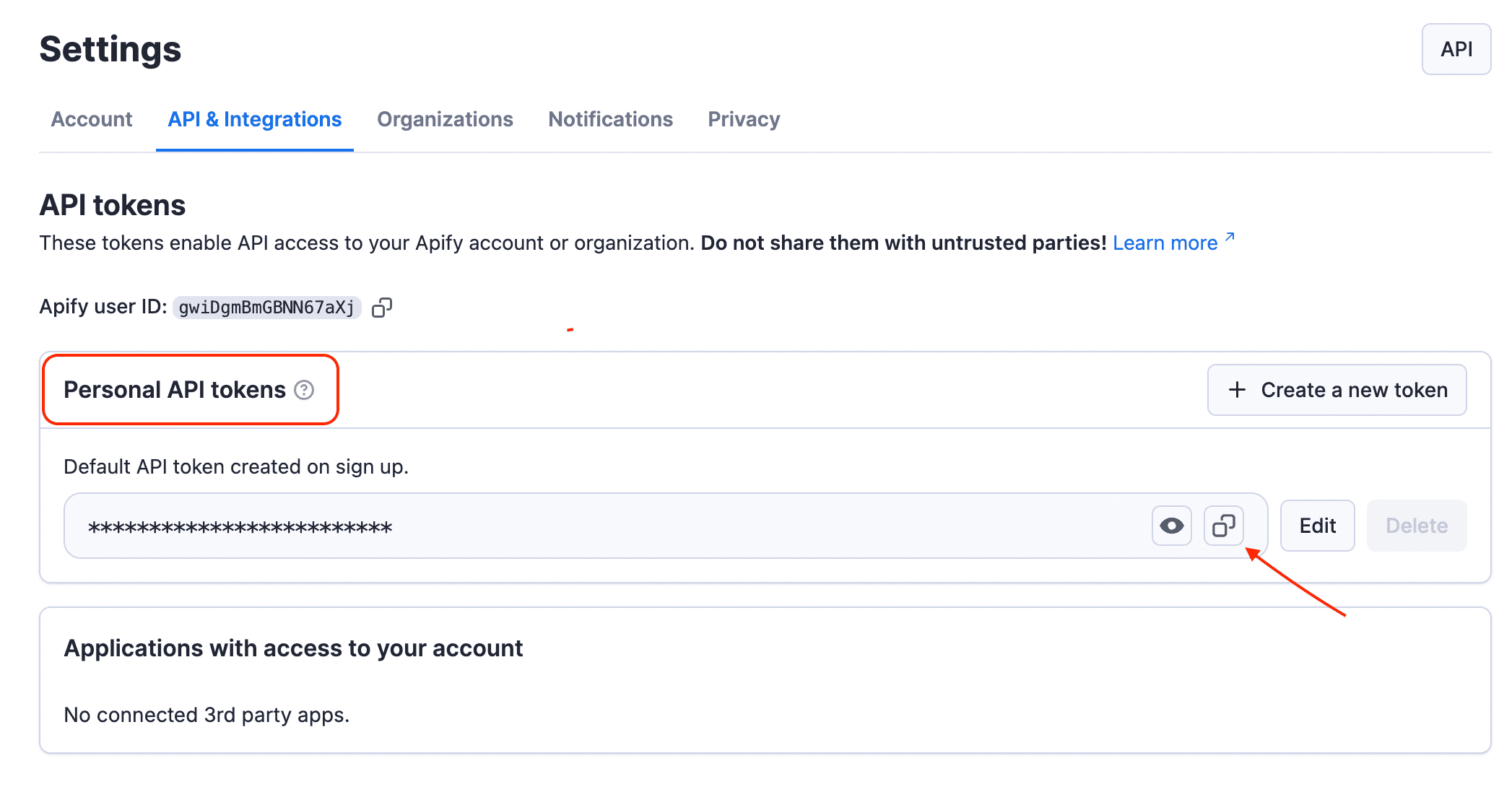
Find your token under Personal API tokens section. You can also create a new API token with multiple customizable permissions by clicking on + Create a new token.
-
Click the Copy icon next to your API token to copy it to your clipboard. Then, return to your n8n workflow interface.
-
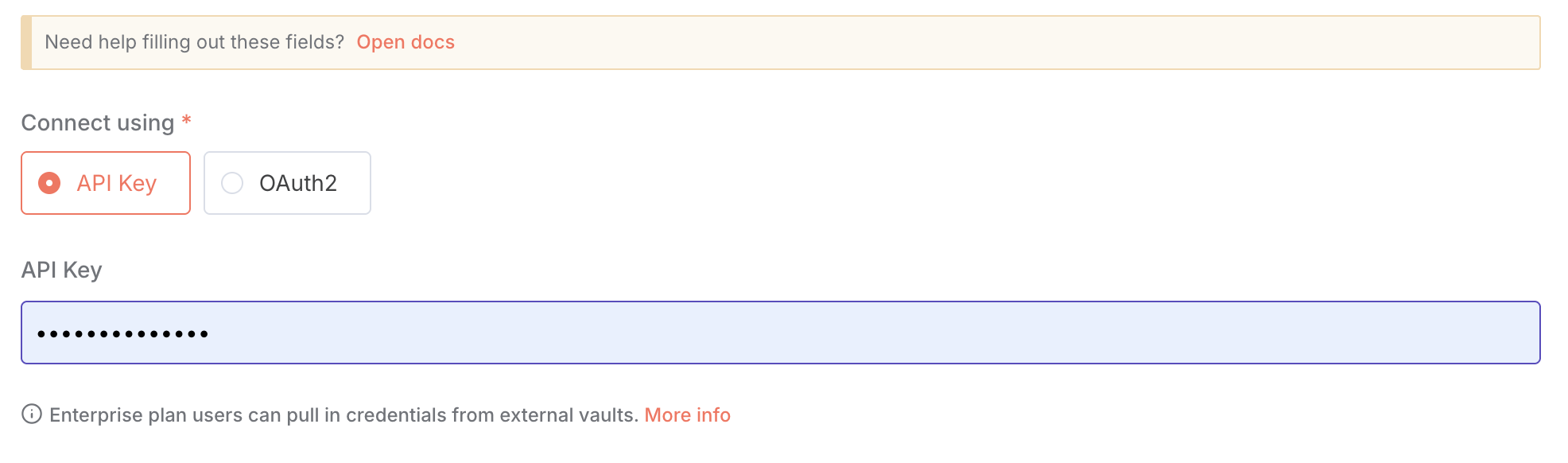
In n8n, click Create new credential of the chosen Apify Scraper module.
-
In the API key field, paste the API token you copied from Apify and click Save.
Website Content Crawler by Apify module
This module provides complete control over the content extraction process, allowing you to fine-tune every aspect of the crawling and transformation pipeline. This module is ideal for complex websites, JavaScript-heavy applications, or when you need precise control over content extraction.
Key features
- Multiple Crawler Options: Choose between headless browsers (Playwright) or faster HTTP clients (Cheerio)
- Custom Content Selection: Specify exactly which elements to keep or remove
- Advanced Navigation Control: Set crawling depth, scope, and URL patterns
- Dynamic Content Handling: Wait for JavaScript-rendered content to load
- Interactive Element Support: Click expandable sections to reveal hidden content
- Multiple Output Formats: Save content as Markdown, HTML, or plain text
- Proxy Configuration: Use proxies to handle geo-restrictions or avoid IP blocks
- Content Transformation Options: Multiple algorithms for optimal content extraction
How it works
the Website Content Crawler by Apify module provides granular control over the entire crawling process. For Crawler selection, you can choose from Playwright (Firefox/Chrome) or Cheerio, depending on the complexity of the target website. URL management allows you to define the crawling scope with include and exclude URL patterns. You can also exercise precise DOM manipulation by controlling which HTML elements to keep or remove. To ensure the best results, you can apply specialized algorithms for Content transformation and select from various Output formatting options for better AI model compatibility.
Output data
For each crawled web page, you'll receive:
- Page metadata: URL, title, description, canonical URL
- Cleaned text content: The main article content with irrelevant elements removed
- Markdown formatting: Structured content with headers, lists, links, and other formatting preserved
- Crawl information: Loaded URL, referrer URL, timestamp, HTTP status
- Optional file downloads: PDFs, DOCs, and other linked documents
- Multiple format options: Content in Markdown, HTML, or plain text
- Debug information: Detailed extraction diagnostics and snapshots
- HTML transformations: Results from different content extraction algorithms
- File storage options: Flexible storage for HTML, screenshots, or downloaded files
{
"url": "https://docs.apify.com/academy/web-scraping-for-beginners",
"crawl": {
"loadedUrl": "https://docs.apify.com/academy/web-scraping-for-beginners",
"loadedTime": "2025-04-22T14:33:20.514Z",
"referrerUrl": "https://docs.apify.com/academy",
"depth": 1,
"httpStatusCode": 200
},
"metadata": {
"canonicalUrl": "https://docs.apify.com/academy/web-scraping-for-beginners",
"title": "Web scraping for beginners | Apify Documentation",
"description": "Learn the basics of web scraping with a step-by-step tutorial and practical exercises.",
"languageCode": "en",
"markdown": "# Web scraping for beginners\n\nWelcome to our comprehensive web scraping tutorial for beginners. This guide will take you through the fundamentals of extracting data from websites, with practical examples and exercises.\n\n## What is web scraping?\n\nWeb scraping is the process of extracting data from websites. It involves making HTTP requests to web servers, downloading HTML pages, and parsing them to extract the desired information.\n\n## Why learn web scraping?\n\n- **Data collection**: Gather information for research, analysis, or business intelligence\n- **Automation**: Save time by automating repetitive data collection tasks\n- **Integration**: Connect web data with your applications or databases\n- **Monitoring**: Track changes on websites automatically\n\n## Getting started\n\nTo begin web scraping, you'll need to understand the basics of HTML, CSS selectors, and HTTP. This tutorial will guide you through these concepts step by step.\n\n...",
"text": "Web scraping for beginners\n\nWelcome to our comprehensive web scraping tutorial for beginners. This guide will take you through the fundamentals of extracting data from websites, with practical examples and exercises.\n\nWhat is web scraping?\n\nWeb scraping is the process of extracting data from websites. It involves making HTTP requests to web servers, downloading HTML pages, and parsing them to extract the desired information.\n\nWhy learn web scraping?\n\n- Data collection: Gather information for research, analysis, or business intelligence\n- Automation: Save time by automating repetitive data collection tasks\n- Integration: Connect web data with your applications or databases\n- Monitoring: Track changes on websites automatically\n\nGetting started\n\nTo begin web scraping, you'll need to understand the basics of HTML, CSS selectors, and HTTP. This tutorial will guide you through these concepts step by step.\n\n..."
}
}
You can access any of thousands of our scrapers on Apify Store by using the general Apify app.
Configuration options
You can select the Crawler type by choosing the rendering engine (browser or HTTP client) and the Content extraction algorithm from multiple HTML transformers. Element selectors allow you to specify which elements to keep, remove, or click, while URL patterns let you define inclusion and exclusion rules with glob syntax. You can also set Crawling parameters like concurrency, depth, timeouts, and retries. For robust crawling, you can configure Proxy configuration settings and select from various Output options for content formats and storage.
Usage as an AI Agent Tool
You can setup Apify's Scraper for AI Crawling node as a tool for your AI Agents.
Dynamic URL crawling
In the Website Content Crawler module you can set the Start URLs to be filled in by your AI Agent dynamically. This allows the Agent to decide on which pages to scrape off the internet.
Two key parameters to configure for optimized AI Agent usage are Max crawling depth and Max pages. Remember that the scraping results are passed into the AI Agent’s context, so using smaller values helps stay within context limits.
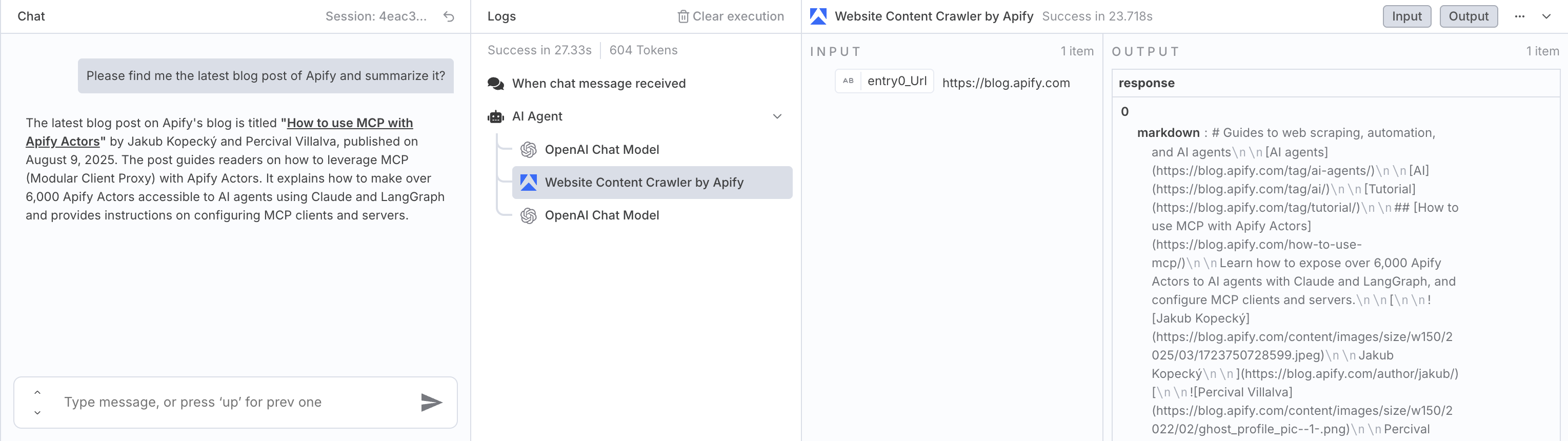
Example usage
Here, the agent was used to find information about Apify's latest blog post. It correctly filled in the URL for the blog and summarized its content.